Proxmox VE 9.2: 7 novidades que realmente impactam PMEs e Engenharia de TI

Proxmox VE 9.2 chegou: 7 novidades que realmente importam (homelab e PME) Publicado em 22 de maio de 2026 — Tempo estimado de leitura: ~15 minutos
O Proxmox VE 9.2 é o release que finalmente fecha algumas das maiores lacunas históricas da plataforma em relação aos hypervisors proprietários. Não tem redesign de interface, não tem feature de marketing pra colocar em apresentação executiva — mas tem um pacote de melhorias operacionais que muda concretamente o dia a dia de quem administra Proxmox em homelab ou em produção de PME.
Balanceamento dinâmico nativo de carga, WireGuard como cidadão de primeira classe no SDN, controle real sobre o HA em janelas de manutenção, modelos de CPU customizados pela GUI, ferramentas pra fazer enrollment dos novos certificados Microsoft 2023 antes de junho de 2026 (esse é prazo, não opcional), e uma atualização agressiva de toda a stack base — kernel 7.0, QEMU 11, ZFS 2.4, Ceph Tentacle. É release de operador, feito pra quem opera.
Neste artigo eu vou passar pelos 7 recursos que considero mais relevantes nessa nova versão, explicando o que cada um faz, por que importa, e como isso se aplica tanto ao cenário de quem mantém um laboratório em casa quanto ao de quem roda Proxmox em ambiente corporativo de PME — que, no Brasil, é provavelmente o nicho onde o Proxmox mais cresceu desde a virada da Broadcom com o VMware.
Se você quiser ir direto pra um tópico específico, aqui está o índice:
- Balanceamento dinâmico de carga (cluster scheduler)
- WireGuard como protocolo de fabric no SDN
- Filtros BGP e EVPN refinados
- Modelos de CPU customizados via GUI
- HA arm/disarm — controle real sobre a alta disponibilidade
- Ferramentas de enrollment de certificados UEFI 2023
- Atualizações de baixo nível: kernel, QEMU, ZFS, Ceph Tentacle
- Considerações sobre o processo de atualização
1. Balanceamento dinâmico de carga: clusters finalmente mais espertos
Essa funcionalidade tecnicamente já tinha aparecido em modo “technical preview” no Proxmox VE 9.1.8, sobre o qual eu escrevi recentemente. Agora, com o 9.2, o dynamic load balancer entra oficialmente como recurso suportado. E sim — isso é grande.
Pra quem nunca passou pela dor de gerenciar um cluster Proxmox no longo prazo, deixa eu contextualizar. Com o tempo, a carga em um cluster naturalmente fica desbalanceada. Você liga e desliga VMs, faz migrations pontuais, cria e deleta workloads. Em algumas semanas, um nó está com 90% de RAM consumida enquanto outro está com 30%. No Proxmox até a versão 9.1, a única saída era olhar manualmente o consumo, abrir a interface, clicar com botão direito na VM, fazer migrate, repetir. Existem projetos da comunidade — o ProxLB, do gyptazy, é o mais conhecido — que automatizam isso muito bem, e eu cheguei a rodar em produção. Mas continuar dependendo de um projeto externo pra uma função tão básica de cluster era um sintoma claro de imaturidade da plataforma.
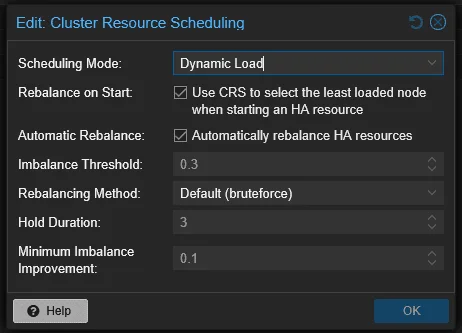
Agora, com o 9.2, o Proxmox passa a oferecer balanceamento dinâmico nativo. Quando o scheduler detecta que um nó está sobrecarregado, ele pode migrar workloads automaticamente para distribuir melhor a carga. Não é o DRS do VMware na sua plenitude — não há políticas de afinidade tão sofisticadas, nem integração com regras de SLA — mas é um passo enorme na direção certa.
Por que isso importa em PME
Aqui é onde o cenário corporativo de PME muda completamente em relação ao homelab. Em um homelab, você é a única pessoa olhando pro cluster, você sabe quando uma VM está consumindo mais que devia, e desbalanceamento na pior das hipóteses te custa um pouco mais de tempo de reação. Em PME, geralmente não existe alguém olhando o consumo do cluster 24 horas por dia. O sysadmin tem outras dez tarefas, e o cluster Proxmox simplesmente é esperado funcionar. Quando um nó fica sobrecarregado por dias sem ninguém perceber, você acaba descobrindo o problema quando uma VM importante começa a ficar lenta, ou pior, quando uma falha de hardware em um nó pesado força um failover que os outros nós não conseguem absorver.
O balanceamento dinâmico resolve essa categoria inteira de problema operacional. Em pequenos clusters de 3 a 5 nós — que é o tamanho típico de PME — a diferença é gritante. Você passa a ter um cluster que se autorregula, e isso libera ciclos do time de TI pra trabalhar em coisas que dão mais resultado pro negócio.
Por que ainda importa pro homelab
Mesmo que você tenha um único host hoje, é quase inevitável que você acabe expandindo pra cluster com o tempo. Eu mesmo comecei com um mini PC e hoje rodo um cluster de 5 nós com Ceph. E quando você chega nesse ponto, balanceamento manual vira um trabalho chato que ninguém quer fazer no fim de semana. Ter isso nativo é uma melhoria de qualidade de vida que você vai apreciar.
Eu acredito que esse recurso, sem grande alarde, vai se tornar uma das melhorias mais apreciadas do Proxmox a longo prazo.
Leitura relacionada: Proxmox 9.1.8 finalmente rebalanceia workloads HA automaticamente.
2. WireGuard dentro do SDN: silenciosamente enorme
Esse é um recurso que muita gente vai passar batido lendo o changelog, e seria um erro. O Proxmox VE 9.2 expande o subsistema de Software-Defined Networking (SDN) adicionando o WireGuard como protocolo de fabric. Pra entender por que isso importa, vale separar duas coisas: o que é o SDN do Proxmox, e o que o WireGuard traz pra essa equação.
O SDN do Proxmox é a camada que permite definir redes complexas em cima do cluster — VLANs, VXLANs, zonas isoladas, EVPN para overlay distribuído etc. Até o 9.1, se você quisesse conectar dois clusters Proxmox em locais diferentes (digamos, um site principal e um site de DR), ou se quisesse esticar uma rede entre seu homelab e uma instância na nuvem, você tinha que montar um túnel VPN separado (IPSec, OpenVPN, WireGuard manual), e por cima dele rodar suas redes SDN. Funciona, mas é mais uma camada pra manter, mais uma coisa pra debugar quando dá problema.
Com o 9.2, o WireGuard vira cidadão de primeira classe dentro do próprio SDN. Você cria um fabric WireGuard direto pela interface, define os peers, e o tráfego do SDN passa por dentro do túnel automaticamente. Isso é particularmente poderoso porque o WireGuard tem características que o tornam quase ideal pra esse cenário:
- Simplicidade: configuração baseada em chaves, sem certificados X.509 nem PKI pra manter.
- Criptografia forte: ChaCha20-Poly1305, Curve25519, design moderno e auditável.
- Performance alta: implementação em kernel, com overhead muito menor que IPSec ou OpenVPN.
- Troubleshooting fácil: menos partes móveis, comportamento previsível.
- Configuração leve: dezenas de linhas, não centenas.
O que isso permite na prática
Pense nos cenários que esse recurso destrava:
- Site secundário de homelab: você tem um cluster na sua casa e quer estender pra casa dos seus pais ou pra uma colocation barata em outro estado. Antes era projeto. Agora é configuração.
- Conectividade híbrida com nuvem: uma VM rodando em VPS na Hetzner ou na DigitalOcean fazendo parte do mesmo SDN que o cluster on-premises. Útil pra rodar serviços expostos publicamente sem expor toda a infraestrutura.
- Testes de DR: manter um cluster secundário em outro site recebendo replicação, com a rede já configurada e pronta pra assumir.
- Kubernetes multi-site: nodes K8s em datacenters diferentes participando do mesmo overlay de rede — com EVPN rodando por cima do fabric WireGuard, você tem overlay L2 onde precisa (encapsulado em VXLAN), e o WireGuard cuida do transporte cifrado L3 entre os sites.
- Nodes Proxmox remotos: filiais menores com um único nó Proxmox, fazendo parte de um cluster maior ou ao menos compartilhando recursos de rede.
Pra PME, esse último caso é especialmente relevante. Muita empresa de médio porte tem filiais — uma indústria com fábrica em uma cidade e escritório em outra, uma rede de lojas, um escritório de advocacia com unidades regionais. Antes, esticar a infraestrutura virtualizada entre esses locais exigia trabalho de redes que muita PME não tem internamente. Com WireGuard nativo no SDN, isso fica acessível.
3. Filtragem BGP e EVPN mais refinada
Ainda no terreno do SDN, o 9.2 traz controle granular de roteamento com route maps e prefix lists para BGP e EVPN. Esse é o tipo de melhoria que parece esotérica até você precisar dela — e quando precisa, sem ela é praticamente impossível operar.
Pra contextualizar de forma simples: em um cluster Proxmox que usa EVPN como overlay, cada nó troca informações de roteamento com os outros usando BGP. Sem filtros, todos os nós aprendem todas as rotas de todos os outros, e isso pode ser exatamente o que você não quer. Em ambientes maiores, com múltiplas zonas, múltiplos tenants, ou segmentação por departamento ou cliente, propagar rota indiscriminadamente é um vazamento de superfície de rede — não exatamente “vazamento de dados”, mas vazamento de topologia, e isso facilita movimento lateral em caso de comprometimento.
Os route maps permitem dizer coisas como: “esse nó só aceita rotas de um determinado prefixo”, ou “essa zona só anuncia rotas pra esses peers específicos”, ou ainda “rejeite qualquer rota que venha com determinada community BGP”. Quem trabalha com redes corporativas reconhece isso na hora — é o mesmo conjunto de ferramentas que se usa em roteadores Cisco, Juniper ou FRR direto.
Onde isso faz diferença em PME
Em PME de tamanho menor (até 50 funcionários, cluster Proxmox de 3 nós), provavelmente você nunca vai precisar mexer nisso. Mas conforme a infraestrutura cresce — múltiplos departamentos com segmentação de rede, filiais com EVPN, MSPs que rodam infraestrutura compartilhada pra vários clientes — esse tipo de controle deixa de ser luxo e vira requisito. Provedores de serviço gerenciado, principalmente, vão se beneficiar diretamente: poder isolar tenants em nível de roteamento, com regras explícitas, é fundamental pra entregar segurança real em ambiente multi-cliente.
Pra quem está no homelab estudando networking — labando BGP, fazendo cursos tipo CCNP, ou só explorando como funciona uma EVPN — o Proxmox 9.2 vira uma plataforma absurdamente capaz pra aprender esses conceitos sem precisar de hardware de roteador caro.
4. Modelos de CPU customizados diretamente na GUI
Esse aqui é um daqueles recursos que parece pequeno, mas que economiza muita dor de cabeça pra quem já bateu de frente com o problema. Com o 9.2, dá pra criar e gerenciar modelos customizados de CPU diretamente pela interface gráfica, no nível de Datacenter.
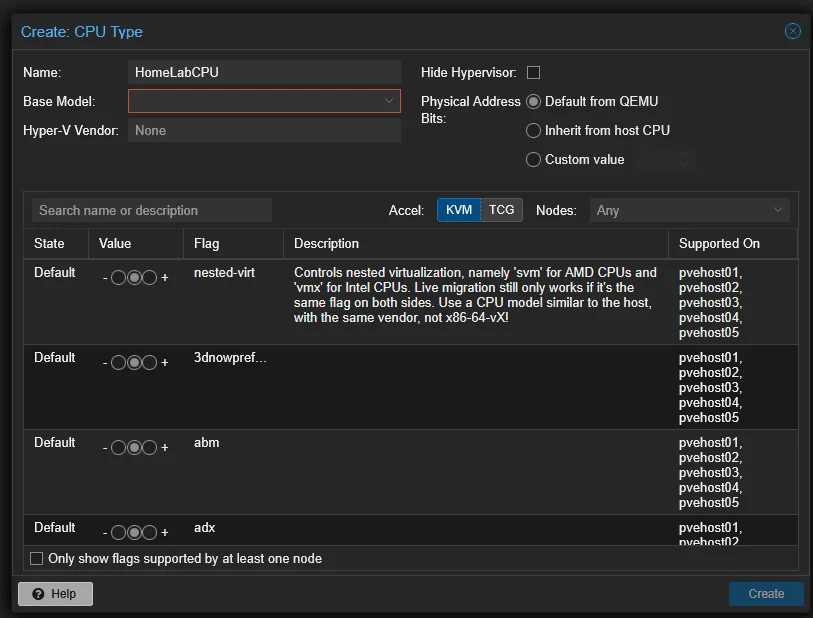
Pra entender por que isso importa, deixa eu explicar o problema. Quando você cria uma VM no Proxmox, escolhe um tipo de CPU pra ela. As opções clássicas são: host (passa todas as features da CPU física pra VM, performance máxima, mas a VM fica “presa” a esse tipo de CPU), kvm64 (CPU genérica, compatibilidade universal, mas performance reduzida porque feature como AES-NI ficam de fora), e os modelos nomeados como Skylake-Server, EPYC-Rome etc.
O problema aparece em clusters heterogêneos. Imagina que você tem um cluster com 2 nós Intel Xeon de gerações diferentes (digamos um Haswell antigo e um Ice Lake novo). Se você criar a VM com CPU host no nó novo, ela vai usar instruções (AVX-512, por exemplo) que não existem no nó antigo. Quando você tentar fazer live migration pra esse nó antigo, falha. A solução tradicional é usar uma CPU “menor”, que existe em ambos — mas aí você joga fora performance no nó moderno.
Os modelos customizados resolvem isso elegantemente. Você define um modelo do tipo “todas as features comuns aos nossos nós”, marca explicitamente quais instruction sets incluir (SSE4.2, AVX2, AES-NI etc.), e usa esse modelo nas VMs. Resultado: a VM usa o máximo de features que o cluster suporta como um todo, e a live migration funciona sem dor.
Antes do 9.2, isso era possível, mas via arquivo de configuração (/etc/pve/virtual-guest/cpu-models.conf) editado manualmente. Agora é um formulário na interface, com uma lista de features disponíveis no cluster pra você marcar e desmarcar.
Atenção: VMs existentes precisam de shutdown
Um detalhe que escapa em vários tutoriais sobre o tema: se você já tem VMs rodando com CPU host e quer migrar pra um modelo customizado, isso não é mudança a quente. Você precisa desligar a VM (shutdown limpo), trocar o tipo de CPU pela configuração, e ligar de novo. Em PME isso significa planejar uma janela de manutenção pra fazer a transição em massa — especialmente em VMs críticas que ficam ligadas 24/7.
Recomendação prática: faça primeiro o inventário das VMs que estão com CPU host hoje (um qm config <VMID> | grep cpu resolve em cada nó), agrupe por criticidade, e ataque em ondas. As VMs sem janela apertada primeiro, as críticas no fim de semana.
Particularmente útil em PME e homelab
Cluster homogêneo é luxo. Em PME, é comum ir comprando servidor conforme o orçamento permite — três Dell R740 em 2020, mais dois R750 em 2023, e em 2025 chega um par de máquinas com Xeon Sapphire Rapids. Todas as gerações coexistem. O mesmo vale em homelab: um mini PC NUC11, outro NUC13, mais um servidor caseiro com Ryzen — combinação interessante de gerações e arquiteturas.
Em qualquer um desses cenários, modelos customizados de CPU passam a ser ferramenta de uso quase obrigatório. Eu escrevi um post separado sobre o tema recentemente, depois de uma série de live migrations que falhavam no meu cluster por exatamente esse motivo. Vale a leitura se você tem cluster heterogêneo.
Leitura relacionada: Live migration no Proxmox falhava até eu corrigir esse setting de CPU.
5. HA arm / disarm: controle real sobre alta disponibilidade
Quem opera Proxmox HA já passou por isso: você precisa desligar uma VM por algum motivo (manutenção, troubleshooting, reconfiguração), dá shutdown na VM, e o HA imediatamente liga ela de novo “porque ela deveria estar rodando”. Aí você desabilita o serviço HA daquela VM específica, faz o que precisa fazer, lembra de reabilitar. Em uma VM tudo bem. Em uma janela de manutenção que envolve várias VMs e múltiplos nós, vira um inferno.
Com o 9.2, o Proxmox introduz o conceito de HA arm / disarm em nível de cluster. Tem um botão na configuração de HA do Datacenter que permite “Freeze” ou “Ignore” o HA inteiro do cluster com um clique.
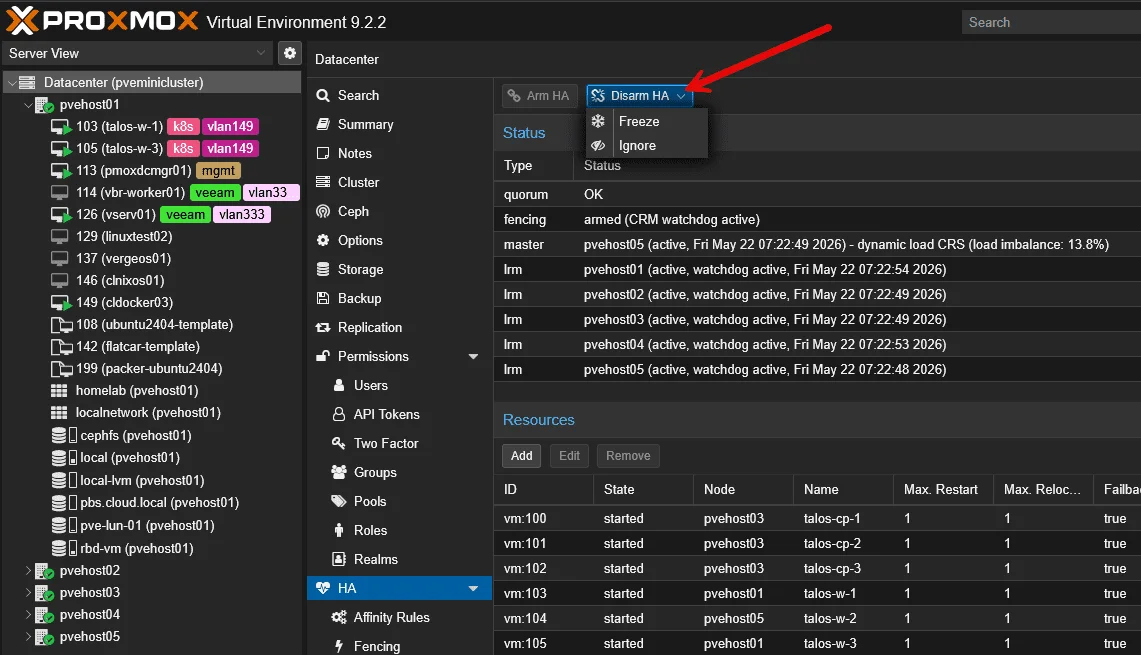
Esse recurso por si só já vale a atualização pra muita gente. Em fluxos de trabalho como:
- Janelas de manutenção: você vai trocar disco, atualizar firmware, reiniciar nó. Desarma o HA antes, faz o trabalho calmamente, rearma.
- Downtime planejado: tem aquela aplicação legada que precisa ficar offline 30 minutos pra um upgrade de schema. Sem HA brigando contra você.
- Troubleshooting: uma VM está oscilando, você quer ela parada pra investigar. HA disarmed, problema isolado.
- Testes de failover controlado: simular uma falha de nó sem o HA reagir nervoso enquanto você observa.
- Upgrades de infraestrutura: particularmente importante quando você está fazendo o upgrade do próprio Proxmox de uma versão maior pra outra.
Cenário típico de PME
Em PME, janela de manutenção costuma ser um fim de semana à noite. O sysadmin entra remoto, tem 3 ou 4 horas pra fazer o trabalho, e a última coisa que ele precisa é lutar contra o cluster. Antes, isso significava lembrar de desabilitar HA por VM, ou subir e descer serviço por linha de comando. Com o arm/disarm, é literalmente um clique antes de começar, e outro pra rearmar quando termina. Workflow muito mais limpo, e menos chance de você esquecer de reabilitar e sair de lá com o cluster sem proteção.
6. Ferramentas de enrollment de certificados UEFI 2023
Esse é um tópico que está passando despercebido pra muita gente, e merece atenção antes de junho de 2026. Resumindo: os certificados Microsoft de 2011 usados pelo Secure Boot estão expirando, e os certificados de substituição (2023) precisam ser enrolados nas máquinas — sejam elas hosts Proxmox, sejam VMs guest com Secure Boot habilitado.
Se você não fizer essa transição, o que acontece? Servidores e VMs com Secure Boot habilitado podem deixar de bootar quando o cert antigo expirar ou for revogado, e atualizações de bootloader assinadas com a chave nova vão começar a falhar. É o tipo de problema silencioso que vai derrubar máquinas em momentos aleatórios, e o sysadmin descobre só no incidente.
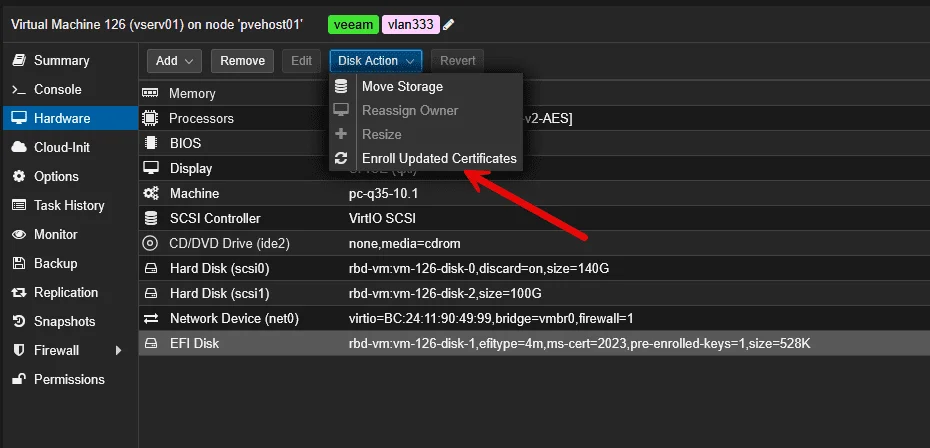
O Proxmox 9.2 expõe esse processo de enrollment diretamente pela GUI. Você não precisa rodar utilitário em linha de comando, gerenciar arquivos .cer manualmente, ou seguir tutorial de cinco passos da Microsoft. Abre a tela, marca a VM ou o host, aplica o cert novo, pronto.
Pra quem já passou pela dor de fazer enrollment de certificado em ambiente VMware, isso aqui parece luxo. No vSphere o processo é envolvente — envolve mexer em EFI variables, às vezes shell de UEFI direto. O Proxmox tornou o procedimento bem mais simples.
Quem precisa se preocupar com isso?
- Quem roda Windows Server em VM com Secure Boot habilitado (que é o default em VM nova).
- Quem tem Windows 11 em VM (Secure Boot é requisito).
- Quem tem hosts Proxmox com Secure Boot ativo no firmware.
- Distribuições Linux modernas com Secure Boot habilitado (Ubuntu 22.04+, RHEL/Rocky 9, etc.).
Eu escrevi um artigo dedicado a esse tema que vale a pena conferir pra entender o tamanho do problema e como fazer a transição de forma organizada — especialmente em ambiente PME, onde você tem dezenas ou centenas de VMs Windows. Tem também a armadilha do BitLocker, que pode fazer suas VMs pedirem chave de recuperação se você fizer o enrollment sem suspender a proteção antes. Não é detalhe a se descobrir no incidente.
Leitura relacionada: Não ignore esse aviso do Proxmox antes de junho de 2026.
7. Melhorias de baixo nível: kernel, QEMU, ZFS, Ceph Tentacle
Os recursos visíveis pela interface são só metade da história. O Proxmox VE 9.2 traz uma atualização agressiva de toda a stack base. Esses números não fazem manchete, mas têm impacto direto no que você consegue rodar e em como o sistema se comporta.
| Componente | Versão no 9.2 |
|---|---|
| Debian | 13.5 "Trixie" |
| Linux Kernel | 7.0 |
| QEMU | 11.0 |
| LXC | 7.0 |
| ZFS | 2.4 |
| Ceph (default) | Tentacle 20.2.1 |
| Ceph (ainda suportado) | Squid 19.2.3 |
Vale a observação sobre o Ceph: Tentacle virou o default, mas Squid continua plenamente suportado pra quem prefere não migrar agora. Não é “alternativo” no sentido de inferior — é uma escolha de timing. Se seu cluster Ceph está saudável em Squid e você não tem janela pra fazer mais uma migração, fica em Squid sem culpa. O Proxmox vai suportar as duas versões em paralelo por um bom tempo.
Por que esses upgrades importam? Resumo do impacto prático componente por componente:
| Componente | O que muda na prática |
|---|---|
| **Kernel 7.0** | Melhor suporte a hardware moderno (CPUs Intel Meteor Lake em diante, AMD Ryzen 8000 series, NICs 25/100 GbE recentes, NVMe Gen5), scheduler aprimorado e melhorias em namespaces e cgroups. |
| **QEMU 11** | Ganhos de performance em virtualização, especialmente em workloads NUMA-aware, e correções de várias categorias de bug em live migration. |
| **LXC 7** | Containers mais leves, isolamento melhor e suporte aprimorado a unprivileged containers. |
| **ZFS 2.4** | Melhorias em ARC, performance de scrub mais agressiva e novas opções de tuning pra workloads de virtualização. |
| **Ceph Tentacle** | Sucessor do Squid: ganhos em RBD performance, rebalancing menos disruptivo e correções importantes no MDS (CephFS). |
O impacto em homelab e PME
Pra homelab com mini PCs modernos (NUC13/14, mini PCs com chips AMD Ryzen 7040/8040, ASRock DeskMini etc.), o kernel novo é o que faz a diferença entre o hardware funcionar plenamente ou ter pequenos problemas de compatibilidade — Wi-Fi não reconhecido, NIC com throughput menor que o esperado, sensores de temperatura faltando.
Em PME, o ganho mais palpável vem do Ceph Tentacle pra quem usa storage definido por software. Pequenos clusters hyperconvergentes (3 a 5 nós com OSDs locais) ganham IOPS sensivelmente, e o rebalancing fica menos disruptivo — o que importa demais quando você está trocando um disco em horário comercial e não quer impactar usuários.
Considerações sobre o processo de atualização
Como qualquer upgrade, dá pra atualizar de duas formas:
- De 8.x pra 9.x: exige procedimento de major upgrade documentado pela Proxmox (caminho específico, scripts de verificação, atenção a configurações descontinuadas).
- De 9.1 pra 9.2: é um upgrade minor padrão. Funciona via interface gráfica (Updates → Refresh → Upgrade) ou via comando
apt update && apt dist-upgrade.
Depois de atualizado, o pveversion mostra a versão nova já em vigor:
Se você ainda está no 8.4, o relógio está correndo
Vale o aviso explícito: a fase de overlap em que o Proxmox 8.4 continua recebendo updates termina em agosto de 2026. Quem está em 8.x e adia indefinidamente o salto pra 9.x vai chegar no segundo semestre desse ano sem suporte, sem patches de segurança, e com cada vez menos documentação atualizada sobre upgrade. Não é cenário pra deixar correr. Se você administra Proxmox em produção e ainda está no 8.4, considere essa janela curta — três meses pra planejar, executar piloto, e rodar o upgrade em ambiente real.
Atenção redobrada se você roda Ceph
Esse é o ponto mais sensível do upgrade. Se você usa Ceph com Proxmox, a ordem das operações importa. Aplicar a sequência errada pode te deixar com um cluster Ceph em estado degradado por horas — em produção, isso é desastre.
O caminho oficial recomendado pela Proxmox, conforme detalhado na thread oficial do fórum sobre o release 9.2, é o seguinte:
- Se você está no Ceph Reef rodando em Proxmox 8.x: primeiro atualize Ceph de Reef pra Squid ainda no Proxmox 8.
- Em seguida, faça o upgrade do Proxmox de 8.x pra 9.x.
- Por último, atualize Ceph de Squid pra Tentacle, já com o Proxmox 9 instalado.
Não pule etapas. Não tente fazer tudo de uma vez. Storage clusterizado precisa de paciência durante upgrades — esses minutos a mais que você “economizaria” pulando a ordem podem custar horas de recovery se algo sair do roteiro.
Em PME isso é especialmente crítico: você tem janela apertada de manutenção, está com pressão pra liberar o ambiente, e a tentação de cortar caminho é grande. Resista. Planeje a janela com folga, execute na ordem certa, e tenha um plano de rollback documentado caso precise voltar.
Checklist antes de atualizar
Independente do tamanho do ambiente, eu sigo essa lista antes de qualquer upgrade de Proxmox:
- Backup completo de todas as VMs e containers (PBS na mão).
- Snapshot do estado de configuração do cluster (
/etc/pveexportado). - Verificação de que o cluster está saudável (quórum OK, todos os nós online, sem alertas no Ceph se aplicável).
- Janela de manutenção comunicada — em PME isso significa avisar os usuários, em homelab significa avisar a família que a Plex pode cair.
- HA disarmed (agora com o novo botão, fica fácil).
- Atualizar um nó por vez se for cluster, esperar voltar saudável antes do próximo.
- Não fazer upgrade em sexta à noite. Sério. Faça sábado de manhã, com café.
Encerrando
O Proxmox VE 9.2 não é um upgrade chamativo. Não tem feature de marketing pra colocar em apresentação executiva. Mas é o tipo de release que melhora a vida de quem opera Proxmox no dia a dia — e isso é o que mais importa numa plataforma de virtualização.
Os destaques pra mim, em ordem de impacto operacional pra um ambiente bem mantido:
- HA arm/disarm — economiza tempo em toda janela de manutenção.
- Balanceamento dinâmico — cluster mais saudável sem babá.
- Custom CPU models na GUI — resolve dor real em cluster heterogêneo.
- WireGuard no SDN — destrava cenários multi-site simples de configurar.
- UEFI 2023 enrollment — não é opcional se você usa Secure Boot. Trate antes de junho.
- Ceph Tentacle — performance e estabilidade em quem usa storage definido por software.
- BGP/EVPN filtering — fundamental se você está num cenário avançado de redes.
Uma observação sobre essa ordem: itens 1, 2, 3 e 4 são qualidade de vida — melhoram seu fluxo de trabalho mas não têm urgência. O item 5 (UEFI 2023) é o único com prazo concreto: junho de 2026. Se sua empresa usa Secure Boot em VM ou no host, esse é o item que você trata primeiro, mesmo que os outros sejam mais empolgantes. Não é negociável, é calendário.
Eu já atualizei os 5 nós do meu cluster de homelab pra 9.2.2, com Ceph Tentacle, e até agora não vi nenhum problema. As coisas que eu mais notei no dia a dia foram exatamente o HA arm/disarm (que eu já usei várias vezes em uma semana) e o balanceamento dinâmico, que pegou meu cluster que estava com um nó mais carregado e suavemente moveu workloads pra equilibrar.
Em PME, minha recomendação é: planeje o upgrade pros próximos 30 a 60 dias, especialmente se você usa Secure Boot (UEFI 2023 não espera) ou Ceph (Tentacle traz ganhos palpáveis). E se você ainda está no 8.4, o relógio do EOL em agosto de 2026 deveria ser motivo suficiente pra colocar isso no roadmap dessa semana — não da próxima.
Se você está planejando o upgrade pro 9.2, lidando com a transição do Ceph Reef → Squid → Tentacle, ou querendo aproveitar o release pra finalmente estruturar SDN entre filiais com WireGuard, esse é exatamente o tipo de projeto que faz diferença quando bem executado — e o relógio do EOL do 8.4 não espera.